A few days ago I had a shot at looking at my topic models for a cybernetics list through Gephi. I’m not sure I got much from the experience but it did point out to me that quite often the topics were a mix of people and ‘things’. I wanted to know if there was an easy way to find which things belong to which people. Following ‘the simplest can sometimes be the best’ (and easiest) mindset I decided to have a look at which words followed which when ‘s was involved.
I found a topic in paper machines called phrase netting and decided to try it on my text. I killed my machine. So while I think of a way to do the technique on large amounts of text that won’t kill my machine I tried it on a handful of documents.
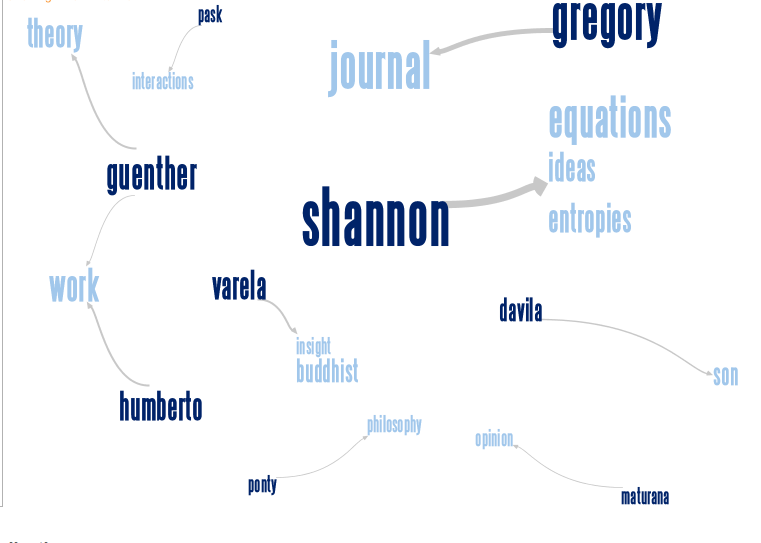
I quite like the idea because it stats to give me an idea of who thinks what, but I was forced to use a very limited amount of text. Something to look into for next time.

0 Comments