Not so long ago I noticed that I am in fact the last person left to discover Topic Modelling/LDA techniques, I have had a mad dash to catch up and get my head around them.
Up until now I’ve spent my time simply getting the technique to work. I started with R’s topicmodel package, moved on to Mallet and then moved back to R but instead using Mallet’s R package. Mallet is fun but its ease of use makes it a dangerous tool. As Ben Schdmit cleverly points out. When you are using a mallet everything looks like a nail, and so far I have been hammering all the data in sight because well, it’s just so easy and gives you a happy feeling.
So on my latest mission to destroy everything with Mallet I tried to step back and think ‘but what does it mean’ and ‘but how do we validate these models?’. To be honest I still have no idea, but I had a go at trying to make sense of it. It didn’t go well.
I thought that the first step in working out how I could evaluate topic models was to use it on data that actually means something to me, well actually something that should be something to me but doesn’t I decided to use the Topic Modelling tools on a Cybernetics mailing this. I work in a Cybernetics department, but it means little too me. For those who are new to Cybernetics this is what I do understand: it is a trans disciplinarily approach to exploring regulatory systems, a special effort is placed on making the approach as inaccessible as possible to new comers (this is a positive feedback loop designed to boost egos of those whom understand). Every so often a ‘new order’ of the approach will be introduced to ensure diversion and encourage hated of each other, followers of each consecutive order must wear pants more ridiculous than followers of the preceding order. However, I didn’t care for such pants and simply wanted to get a better understanding of what it’s about. So to get my head around such a complex subject I though I’d run some of the tools over a cybernetics mailing list.
I scrapped an archive of the mailing list. Looking back there are some mistakes I should have noticed while scraping, I’ve decided to plod on regardless and I’ll fix if I decide to look further into this. These mistakes 1) I’ve not scrapped the whole archives, but just two years as they go back to 1997! 2) I’ve scrapped each message and sometimes messages have remains of previous messages, sometimes they don’t. 3) I need to get better/less lazy at pre processing the data.
After scraping the list I decided against using my collection of R scripts and instead used a Java tool called topicmodellingtool, which is basically front end for Mallets topic modelling functionality. It’s quiet easy to use and spat something out at me pretty fast.
Here I should point out that LDA/Topic Modelling can spit out quite a lot at you. It not only identifies topics of documents, but it also tells you which topics a document belongs to, and what percentage of that document belongs to which topic. I’m going to ignore all that for now and simply concentrate on the topics themselves, because, time.
I had twenty topics; I think it’s important to play with the number of topics and see what it spits out at you. 20 for me seemed to generate some topics that looked reasonable to me (and some that didn’t)
- loet ls leydesdorff images ind net june system dear reply
- cybernetics images ls work ind september people variety post vsm
- id gpia pj aw kpia ncj dqo ig agf gpg
- information hermes gwu theory discussion cybernetics group bernard subject pask
- lines lt roger harnden rogerharnden kauffman nick green oliver gavin
- amp www lt quot org oil umpleby people world stuart
- communication observer robert ind images ls bricks joel observation book
- images ls ind cybcom reply recent previous message proportional td
- pt mze kl vb pv kicagmy db mta mza kq
- distinction joel lou dear kauffman ls ind images distinctions making
- lt amp font gt span size class dmsoplaintext style lang
- information pask energy subject november nick gavin boundary cybcom green
- bd mt wa rt cd mso da dq ai wb
- roger understanding ind ls joel images things time point harnden
- lt span font div style family color pt serif sans
- theory category gavin lou ind ls images ct form dear
- maturana randy observer system living varela ind images work terms
- nick subject november physical green pm process nov model bernard
- cybcom oliver lou structural coupling living ind hermes pm images
- fb bf ce aa ef ad level ab oa ge
I could tell that some of these had bad terms in due to my rubbish pre processing. So did I go back and preprocess it and do it again? No. Lazy me just chucked them out.
I noticed I could see names and then some words you might expect people in silly pants to say. Some of these topics overlap, so I decided to create a simple graph of nodes as words in topics and edges as being the relationship of being in the same topic. It was a 20 minute job and something came out that looked like this:
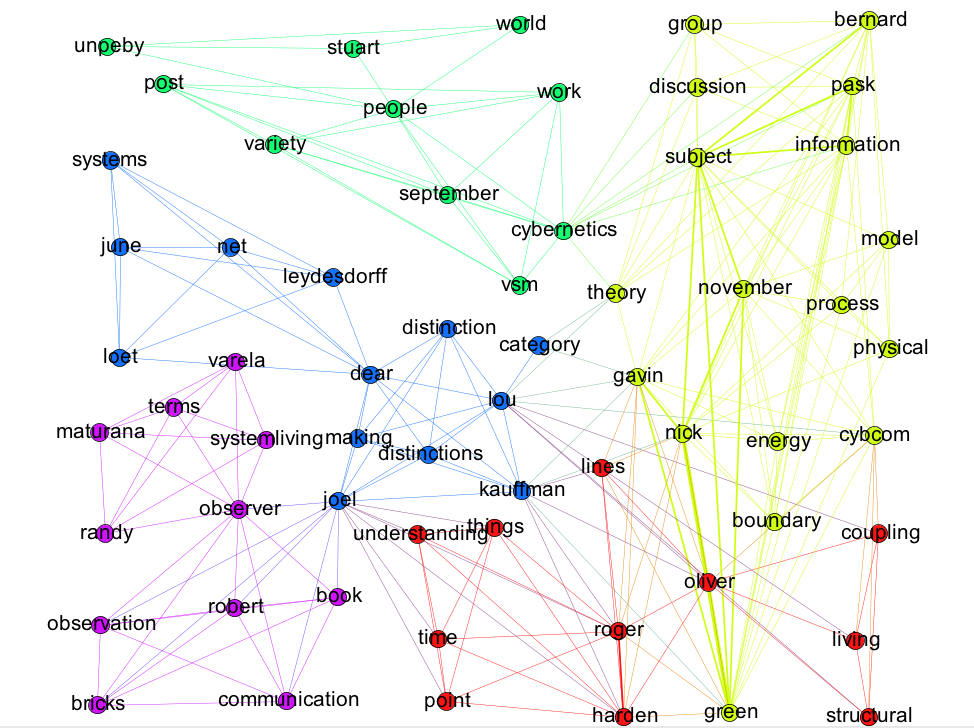
no idea (click to enlarge)
There were some things that were obvious. I noticed that surnames and first names were connected. It also looked like Pask has something to do with information and a theory which is central to cybernetics (along with VSM and work. It looks like understand is central to various topics, and so is an observer. It gave me a vague idea of who is talking about what on the list.
No idea what’s going on. Time to try something different. At least I learnt that pre processing is super important. Also that Topic Models might be a good way to explore data, but might not be a good way to explain it.

0 Comments