If you want to grab comments from one post, the Graph API Explorer might be easier.
I’ve been trying to find ways to poke the Facebook graph that will be easy for people who find working with the API directly difficult and currently I am using a tool called Facepager to extract data. After a few minutes working with the program it seems easy enough to get it to poke the Facebook Graph for the comments and then store them in a SQLite database. I’ll be looking to work with the results in R… but one thing at a time!
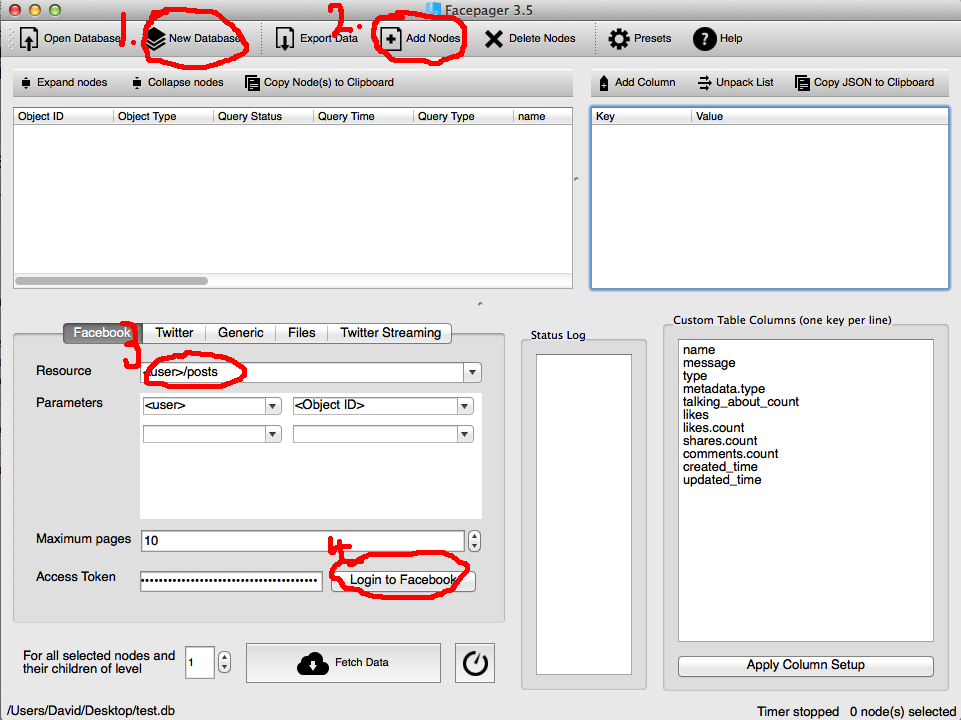
1) After downloading and extracting Facepager for your system you should see a screen like the one in the image. Click the new database button and give it a filename. This will be your SQLite database, I’ll be using this in R in other posts, but for now you can just reload it it in Facepager to do stuff.
2)Then you want to click add node. The node name is the name of the Facebook page you want to explore. For example if you want to get all the comments from posts on the Minecraft page at: https://www.facebook.com/minecraft then the node name is minecraft.
3)Select what you are after in the ‘Resources’ Tab, I went with <page>/posts.
4)You need an access token to get any data out of Facebook, press the login to Facebook button and log in.
5)Press fetch data.
Easy, now you have all the results viewable in Facepager, each post only shows the first 25 comments though and I want them all. To find them all I just clicked each individual node and changed the resource to post/comments. A video on how I did it:
Code
I have been asked in the comments to share my R code. I’m not sure I still have the script in the state it was in during the video, but I did find my finished thing. This script takes all the comments I have scraped from Facebook (from political party pages) and then it finds repeated phrases. If you would like to see what I did with it then you can read this post about it here. Hope it helps.
options(mc.cores=1)
#import packages
install.packages("tm")
install.packages("RWeka")
install.package("slam")
library(tm)
library("RWeka")
library("slam")
#import csv
mydata = read.csv("5partycomments", sep = ";") # read csv file
#prepare text
corpus <- Corpus(VectorSource(mydata$message)) # create corpus object
corpus <- tm_map(corpus, mc.cores=1, removePunctuation)
corpus <- tm_map(corpus, removeNumbers, mc.cores=1)
corpus <- tm_map(corpus, removeWords, stopwords("english"), mc.cores=1)
# convert all text to lower case
corpus <- tm_map(corpus, tolower, mc.cores=1)
#proplem with to lower means we need to make it type of plain text document again
corpus <- tm_map(corpus, PlainTextDocument)
#make the term document matrix
tdm <- TermDocumentMatrix(corpus)
#find the frequent terms
findFreqTerms(tdm, lowfreq = 500)
#tokenizer for tdm with ngrams
BigramTokenizer <- function(x) NGramTokenizer(x, Weka_control(min = 6, max = 6))
tdm <- TermDocumentMatrix(corpus, control = list(tokenize = BigramTokenizer))
findFreqTerms(tdm, lowfreq = 15)
#create dataframe and order by most used
rollup <- rollup(tdm, 2, na.rm=TRUE, FUN = sum)
mydata.df <- as.data.frame(inspect(rollup))
colnames(mydata.df) <- c("count")
mydata.df$ngram <- rownames(mydata.df)
newdata <- mydata.df[order(-count),]
newdata<-newdata[order(newdata$count, decreasing=TRUE), ]

68 Comments
Patrícia Rossini · September 8, 2014 at 5:48 pm
So I need to fetch data from pages with thousands of comments per post. Will Facepager be adequated for that?
Thanks!
David Sherlock · September 9, 2014 at 9:12 am
it has been a while since I’ve used it but I think it depends on how a many pages you want to mine. You might be best just using the facebook graph api. Facepager will help you get started understand the calls so it still might be worth taking a look.
addien · August 3, 2017 at 5:19 pm
Hi david. Can you help me how to design tools to mencrape facebook data just by entering certain keywords then the result is displayed in table form. In the table there are names, addresses, contacts, emails. And then the data can be stored in exel format. Please email me at joey_nemo84@yahoo.com
Ashok Grover · October 12, 2017 at 5:19 am
If you get a suitable reply please forward to my mail id akgr@rediffmail.com
Jakob Jünger · October 25, 2014 at 6:47 pm
Yes, it will 🙂
B Kelly · February 6, 2015 at 9:44 am
I just want to find how many people have an open profile on Facebook i.e.. where anyone can read their details. Could I use face pager for this?
B Kelly · February 6, 2015 at 10:11 am
I’m doing this as a project for college.
nizam · April 9, 2015 at 10:35 am
i wanted to get the data like Pakistani students studying in CHina Beijing, can you guide me how to do that using facepager ???
thanks
nizam · April 9, 2015 at 12:00 pm
I tried to log in, but i cant see login page of facebook after clicking log in to facebook, an empty form is open, and i get this error “Network error (99): Connection timed out” . can anyone tell me how to solve this problem ?
Cracken · July 24, 2016 at 3:04 pm
Seems your internet connection is down
zezosomo · April 30, 2015 at 12:35 pm
thanks
Mario · May 6, 2015 at 6:47 pm
do you mind to share you R code that you show in to the video?
good job man!
David Sherlock · May 6, 2015 at 6:57 pm
Sure, I’m on my phone at the moment. I will look for the code when I’m on my machine tomorrow
Mario · May 6, 2015 at 7:12 pm
awesome! And thank you for the quick turnaround. I really enjoyed the video.
David Sherlock · May 7, 2015 at 7:25 am
I’ve updated the post with some code I wrote in R that uses the a CSV file generated by facepager. If your doing anything interesting and want help/collaboration on a project let me know. hth.
Mario · May 8, 2015 at 1:32 am
awesome & thank you. Count on it.
Thanks again.
;mE
nizam · May 8, 2015 at 10:30 am
can you help me explain how to get login and mine data from facebook, like i want to collect data of people added with me on facebook…
when i try to log in i dnt get log in page… looking forward to your reply..
David Sherlock · May 8, 2015 at 10:41 am
Im not sure what you mean you don’t get the log in page, When you press the button? Can you screen record what you have done so I can see if I can replicate the problem. If it is a software error you might want to contact Till Keyling, it might be best through the github repository for the app but he has been very good replying to me on Twitter at @tkeyling . The other author Jakob Jünger sometimes leaves comments on my blog, but I do not have hos contact details.
I think to start it would be good to exactly identify the problem, is it when you press the log in to facebook button?
nizam · May 9, 2015 at 3:49 am
Yes exactly, when i follow all the steps, and click on the Log in Facebook button i just get an empty window, and some errors are shown like ” SSL certificate error ignored: (Warning: Your connection might be insecure!)
Network error (2): Connection closed” ,
i have a screenshot but i dont know how to send you , as there is no option for attaching photos here.
Ali · May 14, 2015 at 3:48 pm
How to download the software ?
Mario · May 16, 2015 at 8:37 pm
Thx for the source – I am getting an error on Error in order(-count) : object ‘count’ not found
David Sherlock · May 16, 2015 at 8:52 pm
I’ll look in to it for you. Might not be until mid week tho
David Sherlock · May 17, 2015 at 1:44 pm
ok, I cant see what I was trying to do there. I think I was trying to create a dataframe of all phrases and the number of times they were said. I’m trying to order it by the number of times they have been said.
Delete this line:
newdata <- mydata.df[order(-count),]
and change the last line to:
newdata<-mydata.df[order(mydata.df$count, decreasing=TRUE), ]
Pei · June 18, 2015 at 4:36 am
Thx David! You video is so helpful! There’s one more question, can I extract my friends’ action on FB, like post, comments, like? Or I could only extract my friends’ action on my homepage? Trapped with this problem for weeks, hope to hear your suggestions.
Thanks again!
Pei · June 22, 2015 at 4:42 am
Hey David, thanks for your nice tutorial! I just start with Facepager and face some problem. I test with my own FB account following you instruction. But get nothing.
If I write “me” in Add Nodes, then it returns “empty” in Object Type and “fetched (200)” in Query Status.
If I past my user_id in Add Nodes, then it returns “data” in Object Type and “error (404)” in Query Status. If I click into error (404), it gives me following message:
{
“error”: {
“message”: “(#803) Some of the aliases you requested do not exist: me_x”,
“code”: “803”,
“type”: “OAuthException”
}
}
I’m not sure what’s the problem and how to fix it. Grateful if you could help me with it.
Many many thx!
Maissa · August 5, 2015 at 11:30 am
Hello,
I have succefully installed the Facepager and I intend to use the fetched Data to refine it in hortonworks platform. Any help please !
Thanks a lot,
David Sherlock · August 5, 2015 at 11:35 am
Hi, What do you need help with? Hortonworks?
Stephen Smith · August 14, 2015 at 2:32 pm
I am using face pager to pull data help my friend get insights about her customers. I have pulled a list of Facebook users who are attending an event that her business is hosting. Any idea how to pull more Facebook information about the list of users I have? I have their names and Object IDs. Thanks
Somantri · September 7, 2015 at 8:17 am
I still have some error (Query Status) to fetch data from facebook
Somantri · September 8, 2015 at 1:23 am
Thanx for the application… I have an empty message after fetching data. how to fix it?
Mario · September 8, 2015 at 1:25 am
try to with the minecraft example as shown in the video if it does work than there’s something wrong (permission/privacy…) with the settings you’re inputing.
Anupam · September 10, 2015 at 6:17 am
Hi David, How to fetch data from confession page? I am getting error(400) while fetching data from confession page like https://www.facebook.com/JU-Confessions-1609256459297929
Daniel · July 8, 2016 at 1:12 pm
same here 🙁
Ali · October 18, 2015 at 9:24 am
Hi, I downloaded the software and I created a new nod but when I click the login to Facebook to get the access token it opens a blank white window and nothing happens, in the status log it shows the following:
2015-10-18 22:19:35.690000 Network error (99): Connection timed out
Any suggestions how can I fix that,
thanks for the video example
Yanis Giannopoulos · November 14, 2015 at 6:24 pm
Helo
How to query a group I am member of please?
Phạm Duy Blog · January 23, 2016 at 2:56 pm
Thanks for sharing, but How to download the software ?
mariya khan · March 1, 2016 at 5:48 am
hi sir i need ur help in my project
mariya khan · March 1, 2016 at 5:56 am
i am from pakistan peshawar so my project is to extract data from facebook about terrorism its effect on education, children ,Socity ,Ecnomy so i used facepager but i am confused how i save or use for implementation.
Maud · July 27, 2016 at 2:56 pm
Hello David,
I didn’t understand if it works for more than 25 posts ? Is it possible to indicate from which date we would to like collect data ?
Thanks a lot in advance !
And thanks for the video !
Maud
Erin · July 29, 2016 at 3:08 pm
Hi, dear
I try many times, but there is no comments showing up all the time? IS there any problem with my computer?
Thanks for you helpping
Rosa · July 30, 2016 at 10:28 pm
Hello,
I’ve tried many times, but I always get error 404. Any help, please?
Sumit Rawal · August 18, 2016 at 10:36 am
Whenever I am clicking login to facebook on Facepager it is showing HOST NOT FOUND ERROR
Can you please help. Because of this I am still unable to extract data
awhy oghy · September 4, 2016 at 2:56 am
Hi, I’ve tried the software, and it worked just fine. But unfortunately I can only get 50 comments. Is there any way i can get ALL the comments and REPLY, LIKES and COMMENTS for the comments as well. PLUS how to get non-english comments automatically translated into English? Please, I need this for my project. Thanks
Sourire · December 18, 2016 at 7:09 pm
Hi,
I tried to use Facepager to extra post and comments from my Facebook group but I didn’t get it work.
I only got it on my Facebook page. I cannot find any documentation on Facebook group. I could only extract the group members name.
Many thanks in advance for any tips.
Best Regards,
Véronqiue
Nina · February 2, 2017 at 1:34 pm
Hi David,
thank you for your great video. It was a great explanation! 😀 Does FP also have the possibility to download member names of a group and the name of the person who added them to the group?
This would be a great tool to work with 🙂
Maybe you know someone who can point me into the right direction
Thanks a lot 🙂
Nina
Michael dela Fuente · February 27, 2017 at 9:25 am
Hi! I was trying out Facepager to get data for my research and was getting an error(404) and when I check I have this “Cannot query users by their username”. I tried fetching data from “minecraft” and was able to get some data. Does this mean that we can only get data to publicly available FB pages? I tried it with my own FB account and got the same error.
Jakkarin · April 10, 2017 at 1:07 pm
{
“error”: {
“message”: “(#803) Cannot query users by their username (virin.kumlertluck)”,
“code”: “803”,
“type”: “OAuthException”,
“fbtrace_id”: “Gk07mI08Nv5”
}
}
I got this I can’t fetch any data except from minecraft
rasha deib · July 16, 2017 at 8:52 am
hi
I need to fetch data from pages with share counter per post. Will Facepager be adequated for that?
Thanks alot !
semeh · September 18, 2017 at 9:25 am
dear Sir
Thank you very much for the solution however I have some problems when getteing access using the token. When I try to connect to facebook, the connexion is not considered by facepager and my token is not taken.
ari · October 18, 2017 at 7:41 am
I want to scrape comment from user post, can we do this, because it show error not working.
sophia · December 5, 2017 at 12:39 pm
is there another way to get the access token apart from the login button from the facepager? because when i tried to get the login from facepager it gives me an empty page
sophia · December 5, 2017 at 12:45 pm
is there another way of getting the token because i have tried login using the login button from the facepager it gave me empty window
nishant · March 21, 2018 at 1:42 pm
how to find download link
Tahmina · May 17, 2018 at 12:52 am
I am trying to follow instructions from the video to extract data from a fb group that I am a member, however facepager just freezes when I add the id and try to click ok. nothing happens from there onwards.
Anderson O Muniz · June 3, 2018 at 3:16 am
it doesnt connect with fb button. how to solve it ?
Amy · July 26, 2018 at 2:48 am
Can this work in a closed facebook gruop?
Engy · August 12, 2018 at 11:43 am
Hello, David!
Thank you very much for helping us to figure this out. I have learned how to collect data from FB pages. I need to know how to do the same with groups. How can I collect posts and comments from any group? Can you walk me through the process? I would be very grateful.
One more thing, since FB has changed its privacy policy, I no longer can get the name of the commentator which is a terrible thing for my research. Is there any other way/program/app to overcome this problem? I can not use the API Graph because I don’t have the access token of the page since it is not mine. Any clue?
Thank a lot in advance.
Noufan PMC · September 17, 2018 at 5:10 am
Hello,
Thanks for this helpful tutorial, But I’m getting error when I ran the R code,
Can you please help me out on this too, This is the error I’m getting
corpus <- tm_map(corpus, removeWords, stopwords("english"), mc.cores=1)
Error in FUN(content(x), …) : unused argument (mc.cores = 1)
Thank you
Moh · September 28, 2018 at 5:03 am
Hi,
Is there anyway to send those extracted users a bulk message via facebook or form this app?
Bendert de Kloe · December 13, 2018 at 10:32 am
Hey, The section name for me is totally blank. Is it possible to fetch names on mac, or is this a glitch? (I’ve tried from.name and name.)
Pranjal Vatsa · December 25, 2018 at 9:40 am
Is there a way to get the user ids of all users who have engaged with posts on a FB page? We basically want to analyse user data to create user personas for our clients. Further on, is there a way to pull user related data for these users (demographic data, interests etc).?
Serban Tirlea · January 22, 2019 at 3:02 pm
Hi, I want to extract comments to may posts of my facebook page, but Facepager doesn’t give the name or fbk id, or other informations about the commentator. I need these informations, because I want to run a contest and extract the winner. If there are many comments I will need to collect their name manually, or there is another possibility?
Thank you!
Engy · June 24, 2019 at 8:23 am
Hello, David!
Thank you very much for this detailed explanation and for the video.
I would really appreciate it if you updated the Facepager tutorials and make another video about extracting comments from groups.
Thank you very much in advance.
Jason · February 16, 2020 at 11:17 am
Trying to get data from one of my groups but getting this error.
Error ‘error (400)’ for 140312773220685 with message (#10) To use ‘Groups API’, your use of this endpoint must be reviewed and approved by Facebook. To submit this ‘Groups API’ feature for review please read our documentation on reviewable features: https://developers.facebook.com/docs/apps/review..
cb raule · March 11, 2020 at 3:25 pm
Great stuff you have here David.
Can I ask for some pointers if I want to extract data from Facebook Marketplace.
For starters, Facepager does not recognise “marketplace” as an Object_ID, hence would appreciate if you can help identify this.
Basically I want to extract (Browse) posts under a specific category (say “Garden”) of properties for sale found in a specific Location (or Locations), the price, description and if possible the url of the advert. Grateful if you can provide the Resource, Parameters and Column names to use in Facepager. Looking forward to your help. Much thanks in advance.
Marco · May 18, 2020 at 1:51 am
Hi David,
First, let me thank you for everything its being really useful.
David, I was having issues capturing all the comments in a single post, I was only being able to capture the first 20 or so comments. Now I am having the issue I am only been able to capture the last 3 o 4 posts
The recurring phrases of BNP members. | David Sherlock · June 19, 2014 at 4:30 pm
[…] I wanted to find out what people were saying on the facebook pages of extreme political parties. At this stage I wasn’t bothered so much about what the party was saying, but what the comments on the posts where saying. The task was to find n-grams in a CSV file and I decided to do it in R. Originally the CSV was created from comments on 10 pages of BNP Facebook posts, I generated the CSV quite quickly using an application called FacePager, it was very easy to do and if you are interested you can find instructions on this post here. […]
Storing Facebook comments from post for analysis - David Sherlock · September 11, 2015 at 2:43 pm
[…] had a lot of feedback from my post detailing how to use Facepager to explore comments on facebook pages. While Facepager is a neat little tool I get a lot of feedback saying that users have difficulty […]