Recently I have following some chatter around the data generated around ourselves, Mark blogged about a personal corpus and I enjoyed this post about a person as an API . The central theme I’ve taken from these posts is around things that tell us about ourselves using data we weren’t even aware we were generating.
As part of a work project I’ve been hacking (playing) around with R in an attempt to find ways to penetrate his data. The problem is this: if we don’t know we are generating it, how do we analyse it? As always the way I’ve made a start is by playing with stuff and while I’ve not got very far yet it is about that time when it is worth standing back and working out what’s going on. As such, this post comes with a warning; I’m simply writing about how far I’ve got to help myself think about the next steps from here. Many of my scripts are not consistent (to stem or not to stem? That is the text miners question) and what I’m doing at the moment isn’t very deep. I’m not going to speak about the many scripts I have that seem to generate rubbish. Gremlins ahead.
I’ve started the personal corpus analysing tool by looking at my own interactions with technology. I started by writing a tool to study things we create (blog posts, tweets), and things we consume (news sites, Reddit).
Things we create
I started by writing a few scripts that can grab data from various sources such as blog/microblog platforms and tried some text mining techniques out on them.

Term R heatmap of this blog. Click to enlarge
The heatmap above shows the most used terms (I used stemming that time..) on this blog and how often they appeared in each document. I like this way of looking at things more than I thought I would because: 1) The documents are in post order so I can identify bits in time when certain words crop up. 2) It’s easy to see where words crop up together (play and games). I think what this also makes me realise is that I need to start thing about phrases rather than just single words, which is a complaint I have about most the other techniques I’ve tried and is something I should keep in mind.
I also followed Ben Marwick’s work and tried some topic modelling techniques on my blog. Basically I use a tool called Mallet to generate topics that my posts may be about. It can’t actually tell me what the topic name is, because, well how would it know? But it can tell me phrases that are going to crop up in each topic and how likely each phrase is to appear:
- “game games href blockquote rift”
- “https://davidsherlock.co.uk/wp-content/uploads png width screen-shot nbsp”
- “api things access time post”
- “blockquote topic corpus.p words documents”
- “i’m href people data it’s”
Topics from my blog
Since my blog is relatively new and I tend to only do small posts I only asked Mallet to give me 5 topics with 5 words in each topic. While I think this might be handy for searching the web for similar content (which I will get to later) this made me realise I have to get a bit better with my stop words; nbsp, blockquote and href are perhaps not that important to the topic.
As far as working with things we create goes I’m currently in the middle of writing a bit of code that scrape Google Scholar. Other than thatI think I need to go back and improve on the teqnuies I’m using.
Things we consume
I had a feeling that the things we consume have an effect on us as much as the things we create so I started to look at some of the sites I interact with regularly such as Reddit or Youtube. It occurred to me though that it might be more interesting to see what other people make of the resource than mining the resource itself so I looked to the comment sections of these sites as a starting point. I started by using my topic modelling code on Reddit comments (which I already posted about here). I found this interesting because sometimes the topics seem to match up to similar topics on my blog, but other times it didn’t tell me much about the topic of a Reddit article but more about mood towards an article (comments belonging to topic “I couldn’t wouldn’t give fuck).
Whats Missing?
While this is all well and good, the original point of this exercise was to find out things about me that I didn’t already know about. I think to do this I need to stop looking at whats there and work out what isn’t there. It might be an odd idea to mine redundancy but what’s not in somebody’s blog might tell you just as much about them as what’s not. To find out what’s not there I’ve started on two scripts. The first script simply does the same analysis to blogs of people you know and tells you the difference in it’s analysis. The image below shows an analysis of 50 posts from my blog to 50 from Mark Johnson and 50 from Sheila MacNeill. It has been weighted to take into account who is the author of each post.
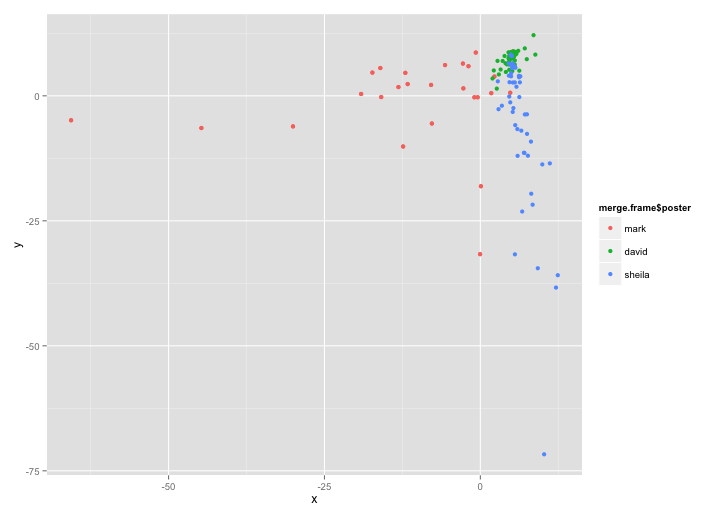
Blog post similarity (click to enlarge)
I like this sort of thing because it show’s where I am in relation to everybody else. In the image above my posts (in green) all seem to be about a similar topic. I guess this is because I do short posts and my blog posts have been in a short amount of time. Still, I seem to be a broker between the things that Sheila talks about and the things that Mark talk about.
My second set of missing data scripts revolve taking the topics that I’ve identified (from the topic modelling) and automatically searching the web for similar content. The scripts then analyse this content and tell me what I’m missing; what I’m not talking about that the rest of the world is. But these haven’t been coded up yet…
Recursion
Finally I want to take all the topics, models and start again. Can I make topic models of topic models? I think it’d be really interesting if we can find out what lies beneath. Think Inception text mining.
To Do
Theres still lots to do.
- My project at the moment exists as a bunch of unorganised scripts. I need to sort it and put it in github.
- The scripts themselves are basically a collection of cool things other people have done that I’ve stolen. I’ve tried to acknowledge people in previous blog post when I’ve borrowed their stuff, but I still, I should make sure credit is given in scripts before I push to github.
- Work with ngrams as well as single words
- Chuck out stuff that didn’t work too well (mostly twitter stuff. theres only so much location based stuff I should have in my scripts)
- Standardise the way I do things (Just decide if I’m going to stem or not!)
- Blog about each of my little scripts showing how they do what they do.
- Finish of the Google Scholar script
- Finish off my scripts for searching the web
- Start thinking about recursion
- Hmm best start thinking about validation…

Self shot of me playing with stuff in R

1 Comment
3D worlds on the web using the Oculus Rift: attempt 1 | David Sherlock · October 10, 2013 at 1:33 pm
[…] from here , mucked around with reading some text from some topic modelling scripts I ‘prepared earlier‘ and downloaded the Oculus Bridge: to create a very rough 3d City featuring random words […]