Recently I’ve been playing with an R wrapper for a machine language library called Mallet to generate lists of topics from a series of text documents. The technique is called Topic Modelling and I have gotten to grips with it from Ben Marwick‘s readings of archaeology papers which has some excellent reusable code. A topic in my model is simply a collection of words that make up the topic. Mallet can do all sorts of fancy things with the words and topics, it can tell me how likely a word is to appear in the topic, analyse text and tell me how much of that text belongs to which topics.
The reason I like it is because the algorithm implemented in Mallet that I use to generate the topics is probabilistic; this leads to some crazy and funny topics. There are also lots of parameters such as number of words in a topic, number of topics and number of runs of the algorithm. Changes to these parameters seem to have a big affect on what comes out the other end. I guess the process has lots of scope to crash and burn, and I like that. Remember: Losing is fun.
This morning I had a go at using topic modelling techniques to write a script that could tell me what people in similar communities talk about. I though this would be a useful tool to ask things like ‘What Mooc should I take next?’. I think my experiment failed, but I guess in the spirit of Losing is Fun though I’d post it anyway.
The Problem
I thought I’d start with Reddit communities since I’m familiar with them. The idea of a Reddit communities (called subreddits) is simple, to post content from elsewhere on the web and then have a good natter about it.
The website Reddit has lots of subreddits, often they overlap or a new community rises out of discontent with an existing community. I decided to use my script to generate a bunch of topics over a few related subreddits and then work out which subreddit talked about which topic most and where the related subreddits overlaped. Since I am interested in what people are talking about I decided to use the comments themselves as the basis for the topics. I mined these using a script provided by user Snotaphilious . The comments were taken out of the top 10 posts from each subbreddit from the last week. I haven’t checked how many comments there are for each post, but the top posts typically have quite a few.
Attempt 1: r/politics r/ukpolitics r/shitpoliticssays and r/conspiracy
I started by comparing the comments from 4 subreddits, these were r/politics a subreddit for U.S political news and information, r/ukpolitics a subreddit for U.K political news, r/shitpoliticssays which describes itself as a ‘subreddit dedicated to pointing out the hypocrisy, arrogance, and bias of /r/politics‘. Finally I threw in r/conspiracy which is where the conspiracy theorists hang out. I set my script to pull back 30 topics with 5 keywords each, here they are:
[1] "law state states drug rights" [2] "food trans fat fats eat" [3] "women love man wife christ" [4] "it's people don't that's good" [5] "wall card family son palestinian" [6] "nsa information government security data" [7] "significant don't conservatives attacks there's" [8] "government congress power corruption money" [9] "people israel don't he's hate" [10] "points ago point days day" [11] "hidden ago score hours minutes" [12] "attack book thousands site ddos" [13] "male issued vote student texas" [14] "time years i'm i've day" [15] "party vote republicans republican democrats" [16] "tools stone diamond tool diorite" [17] "people don't it's i'm make" [18] "wage oil minimum companies food" [19] "paul socialism means rand word" [20] "war middle american east class" [21] "reddit post comment deleted read" [22] "system voter vote voting political" [23] "health people insurance government care" [24] "life man evil good power" [25] "cut lavabit fed government key" [26] "money tax government pay taxes" [27] "conspiracy people i'm israel government" [28] "time call cancer list brothers" [29] "police cops cop dog students" [30] "conspiracy story evidence view remember"
These topics sound right when you think of the context of the subreddits I described above. By casting an eye over them you would also think you would be able to place some of these topics to being used in certain cases, for eaxample topic [30] “conspiracy story evidence view remember” belonging to /r/conspiracy. To see if I was placing the topics correctly I tried to plot the topics along with the average proportions of each topic across all comments for each subreddit:
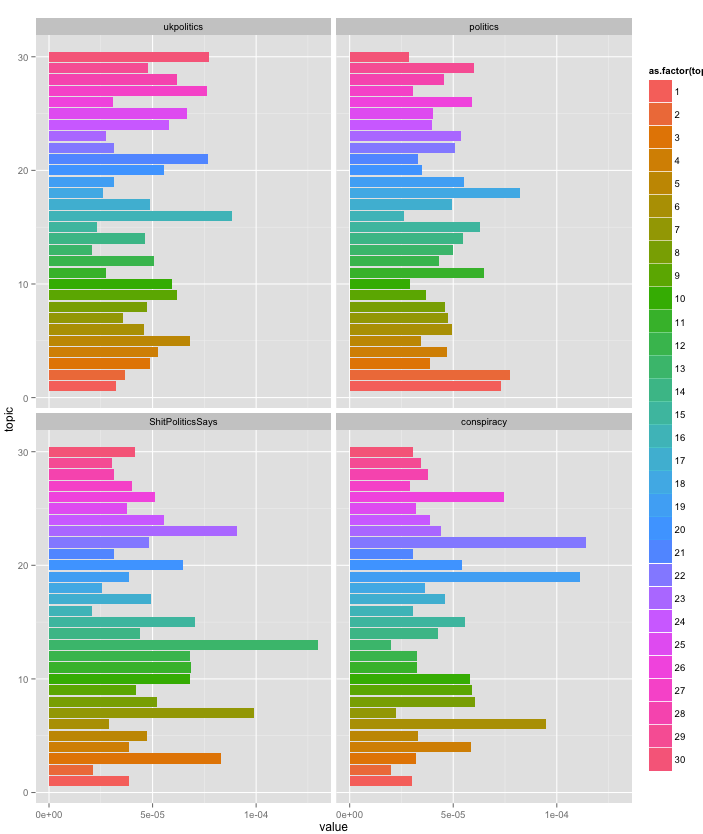
average proportions of each topic across all comments for each subreddit
This is really odd and doesn’t really back up what my initial glance told me. In fact topic 30 was seen least in r/conspiracy and most in r/ukpoltics (I’ll try not to think why). R/conspiracy’s biggest topic was [22] system voter vote voting political. Which was also pretty big in /politics and r/shitpolitcssays. I guess this makes sense with conspiracy theories about rigged elections, r/politics talking about elections and r/shitpolitics says mocking conspiracy theorists. The biggest one topic belonging to one subbreddit but not others was [13] “male issued vote student texas” belonging to r/shitpoliticssays. From what I gather with the Reddit audience being young leftish adults there is often hive mind south state bashing in r/politics and this could be ridicule of that.
I don’t know why topic [12] “attack book thousands site ddos” seems to be the topic that appears most crosses all subreddits the most, perhaps it could have been about site outage that effected them all.
Attempt 2: r/gaming and r/truegaming
At some point the users of subreddit r/gaming got annoyed that the most upvoted content was consistently pictures of N64 cartridges with the caption ‘look what I found in the loft’ and decided to break off and create a subreddit around gaming discussion only, /truegaming. Again I ran the script over r/gaming and r/truegaming to see what the users were talking about in each forum and how it differed.
[1] "points ago years point days" [2] "xbox kinect microsoft console hardware" [3] "shit fuck give edit god" [4] "character build make gear weapons" [5] "reference view space women brain" [6] "movie movies satan living hit" [7] "mario remember super kid playing" [8] "system players player weapons skill" [9] "people they're diablo worst evil" [10] "rts games casual players competitive" [11] "time half left guild years" [12] "i'm it's you're idea isn't" [13] "game it's games don't people" [14] "game review series previous reviewer" [15] "batman related gaming kill joker" [16] "map maps destruction imagine building" [17] "pokemon type types water dark" [18] "hand controller bullet controls screen" [19] "games console system graphics gaming" [20] "video post youtube comment don't" [21] "story game games character player" [22] "pizza live american germany copyright" [23] "blah literally monster madness bundle" [24] "drive life car real race" [25] "money buy game games people" [26] "it's doesn't design true sense" [27] "servers issues problems launch day" [28] "game hard isn't it's difficulty" [29] "lee dies templars assassins creed" [30] "world wow player single content"
Again with the pretty picture:

average proportions of each topic across all comments for each subreddit
The topics generated from comments in the two gaming subreddits, I think this time the two are more closely aligned and it’s quite hard to single out topics belonging to one community and not the other. There are two which stand out, [9] people they’re diablo worst evil” seems to be big in truegaming but not gaming, and vice versa for [17] “pokemon type types water dark” . Does one talk about Diablo (and how they hate it?) and the other about Pokemon?
Why it doesn’t work so well
There were some topics cropping up in subreddit comments I’d expect but there was a lot that seemed random, also all topics seemed to appear in all subreddits.
To be honest I think there is problem with the approach. Each of my Topics has 5 words on it, but each comment on Reddit is very short, quite often there is less than 5 words in the whole comment, the technique does not seem great over small bits of text. Perhaps analysing the content being posted instead of the comments around the posts would be more effective. Still, I’ll have another play with this code changing some of the variables like using less labels per topic and checking things like the amount of comments I’m analysing per subreddit, perhaps there are simply more comments in some subreddits and that is making my results a bit squiffy. The amount of comments might also mean I need more or less topics; I guess usually I’d do this sort of thing with a few large documents talking about a few related things, whereas here I have lots of comments around lots of different things.
I’m still really interested in mining the comments, so if you have any ideas please fire away.
My extremely rough code with bits borrowed from Ben, Snotaphilious and the Mallet documentation:
[codesyntax lang=”text”]
subreds<-c("truegaming","gaming")
documents<- data.frame(
text=character(),
id=character(),
subredit=character(),
stringsAsFactors=FALSE)
time="week"
for(loop in 1:length(subreds)){
print(subreds[loop])
if (subreds[loop] == 'allTop') {
url <- paste('http://www.reddit.com/top/?sort=top&t=', time, sep = "")
} else {
url <- paste("http://www.reddit.com/r/", subreds[loop], "/top/?sort=top&t=", time, sep = "")
}
doc <- htmlParse(url)
#######################################################
# 2. Get the links that go to comment sections of the posts
links <- xpathSApply(doc, "//a/@href")
comments <- grep("comments", links)
comLinks <- links[comments]
comments <- grep('reddit.com', comLinks)
comLinks <- comLinks[comments]
#######################################################
# 3. Scrape the pages
# This will scrape a page and put it in to
# an R list object
textList <- as.list(rep(as.character(""), length(comLinks)))
docs <- getURL(comLinks)
for (i in 1:length(docs)) {
textList[[i]] <- htmlParse(docs[i], asText = TRUE)
textList[[i]] <- xpathSApply(textList[[i]], "//p", xmlValue)
}
#######################################################
# 4. Clean up the text.
# Remove the submitted lines and lines at the end of each page
for (i in 1:length(textList)) {
submitLine <- grep("submitted [0-9]", textList[[i]])
textList[[i]] <- textList[[i]][{(submitLine[1] + 1):(length(textList[[i]])-10)}]
}
# Removing lines capturing user and points, etc.
# Yes, there could be fewer grep calls, but this made it
# easier to keep track of what was going on.
for (i in 1:length(textList)) {
grep('points 1 minute ago', textList[[i]]) -> nameLines1
grep('points [0-9] minutes ago', textList[[i]]) -> nameLines2
grep('points [0-9][0-9] minutes ago', textList[[i]]) -> nameLines3
grep("points 1 hour ago", textList[[i]]) -> nameLines4
grep("points [0-9] hours ago", textList[[i]]) -> nameLines5
grep("points [0-9][0-9] hours ago", textList[[i]]) -> nameLines6
grep('points 1 day ago', textList[[i]]) -> nameLines7
grep('points [0-9] days ago', textList[[i]]) -> nameLines8
grep('points [0-9][0-9] days ago', textList[[i]]) -> nameLines9
grep('points 1 month ago', textList[[i]]) -> nameLines10
grep('points [0-9] months ago', textList[[i]]) -> nameLines11
grep('points [0-9][0-9] months ago', textList[[i]]) -> nameLines12
allLines <- c(nameLines1, nameLines2, nameLines3, nameLines4,
nameLines5, nameLines6, nameLines7, nameLines8, nameLines9,
nameLines10, nameLines11, nameLines12)
textList[[i]] <- textList[[i]][-allLines]
textList[[i]] <- textList[[i]][textList[[i]]!=""]
textList[[i]] <- tolower(textList[[i]])
}
# Let's simplify our list. Could have been done earlier, but so it goes.
allText <- unlist(textList)
# Remove the punctuation, links, etc.
allText <- gsub("https?://[[:alnum:][:punct:]]+", "", allText)
allText <- gsub("[,.!?"]", "", allText)
#allText <- strsplit(allText, "\W+", perl=TRUE)
rm(alldocuments)
alldocuments<- data.frame(
text= allText,
stringsAsFactors=FALSE)
alldocuments$text <- allText
alldocuments$id <- make.unique(subreds[loop])
alldocuments$subred <- subreds[loop]
documents <- rbind( alldocuments, documents)
}
require(mallet)
mallet.instances <- mallet.import( documents$text , documents$text , "en.txt", token.regexp = "\p{L}[\p{L}\p{P}]+\p{L}")
## Create a topic trainer object.
n.topics <- 30
topic.model <- MalletLDA(n.topics)
#loading the documents
topic.model$loadDocuments(mallet.instances)
## Get the vocabulary, and some statistics about word frequencies.
## These may be useful in further curating the stopword list.
vocabulary <- topic.model$getVocabulary()
word.freqs <- mallet.word.freqs(topic.model)
## Optimize hyperparameters every 20 iterations,
## after 50 burn-in iterations.
topic.model$setAlphaOptimization(20, 50)
## Now train a model. Note that hyperparameter optimization is on, by default.
## We can specify the number of iterations. Here we'll use a large-ish round number.
topic.model$train(500)
## NEW: run through a few iterations where we pick the best topic for each token,
## rather than sampling from the posterior distribution.
topic.model$maximize(10)
## Get the probability of topics in documents and the probability of words in topics.
## By default, these functions return raw word counts. Here we want probabilities,
## so we normalize, and add "smoothing" so that nothing has exactly 0 probability.
doc.topics <- mallet.doc.topics(topic.model, smoothed=T, normalized=T)
topic.words <- mallet.topic.words(topic.model, smoothed=T, normalized=T)
# from http://www.cs.princeton.edu/~mimno/R/clustertrees.R
## transpose and normalize the doc topics
topic.docs <- t(doc.topics)
topic.docs <- topic.docs / rowSums(topic.docs)
## Get a vector containing short names for the topics
topics.labels <- rep("", n.topics)
for (topic in 1:n.topics) topics.labels[topic] <- paste(mallet.top.words(topic.model, topic.words[topic,], num.top.words=3)$words, collapse=" ")
# have a look at keywords for each topic
topics.labels
# create data.frame with columns as authors and rows as topics
topic_docs <- data.frame(topic.docs)
names(topic_docs) <- documents$id
require(reshape2)
require(ggplot2)
topic_docs_t <- data.frame(t(topic_docs))
topic_docs_t$thread <- documents$subred
df3 <- aggregate(topic_docs_t, by=list(topic_docs_t$thread), FUN=mean)
df3 <- data.frame(t(df3[-32,-length(df3)]), stringsAsFactors = FALSE)
names(df3) <- c("truegaming","gaming")
df3 <- df3[-1,]
df3 <- data.frame(apply(df3, 2, as.numeric, as.character))
df3$topic <- 1:n.topics
# which topics differ the most?
df3$diff <- df3[,1] - df3[,2]
df3[with(df3, order(-abs(diff))), ]
# plot
df3m <- melt(df3[,-4], id = 3)
ggplot(df3m, aes(fill = as.factor(topic), topic, value)) +
geom_bar(stat="identity") +
coord_flip() +
facet_wrap(~ variable)
## cluster based on shared words
plot(hclust(dist(topic.words)), labels=topics.labels)
[/codesyntax]

5 Comments
Matt · November 11, 2013 at 8:01 pm
Could you add the topic indices to each bar with a geom_text? It’s a little difficult to see which bar corresponds to what.
David Sherlock · November 11, 2013 at 8:09 pm
Thanks for the feedback. You are right, It also doesn’t help that the label on the right is upside down if that makes sense. I’m going to have a play and see what I can do to make it more readable. I’m interested in ways of visualising topic models but finding it difficult so I’d be interested in any other ideas you have
tim · January 13, 2014 at 5:53 am
Looks like you had fun playing with the data. The color doesn’t really seem to add anything extra, unless maybe you sort the columns by high to low frequency. Mallet looks really cool too, I’m definitely going to check that out! Thanks for posting
Karina Bunyik · April 2, 2014 at 5:33 pm
I’m using Mallet on Twitter to model topics. Tweets are in many sense similar to the comments you mine so I might have some us full info. Each topic you have doesn’t consist of only 5 topics, it’s a distribution of all the words used in your data. In other words if some of the 5 word topics don’t make sense, try 10, 15 or even 20. I’m not sure how to set that in R, but its possible. As for the shortness of the comments: aggregate the comments into larger documents. There are numerous articles about Mallet’s topic modeling algorithm called LDA performing better on larger document sizes. How you aggregate your documents, by user, day or subreddits, is a state of art technique. You have to try. Finally about the number of Tweets: try from 10 to 200. You have to run your data for come different topic numbers and then take a look at the topics and see if they make sense. If many topics seem to be about very different topics, higher the number of topics; if you see your topics correspond more to objects and some themes are grained to a few topics, try increasing your topic number. Hope this helps, don’t give up!
David Sherlock · April 2, 2014 at 7:51 pm
Thanks for the useful and very in depth feedback! That is how I understood the topics, have you seen this introduction: http://www.cs.princeton.edu/~blei/papers/Blei2012.pdf ? I think it’s really good. If you are interested in how to set the number of topics in my example I’ve done it here:
n.topics <- 30
topic.model <- MalletLDA(n.topics)
I think you are right that part of the art is working out how you organize documents and set paramaters.
I still don't understand 'Hyperparameter Optimization'. Do you understand what that does?
thanks for the encouragement!