There is a great text mining package in R called ‘tm’. This is a short introduction to tm and how it can be used to create what is called a Document-Term Matrix, which is a matrix showing the frequency of terms over a collection of documents. While this is quite basic it’s hopefully going to be the base of some future work into classification of documents. A video is on its way, but here are my text notes for now:
Tools
The Documents:
I had 15 documents, each document is a description of an episode of popular soap coronation street taken from the spoilers website dailyspy. That’s 3 weeks worth of story lines!
R studio:
I use R studio because it makes things nice and easy, but this isn’t a must.
Process
First I set my workspace in Rstudio via workspace->setworkspace and placed a directory CS in there. CS contains all the documents of Coronation Street spoilers. I started a new R script where I imported the tm library, imported the documents and checked the length of the corpus.

I used the tm_map function to check for stop words, strip whitespace, remove punctuation/numbers and set as lowercase.

From there it is quite easy to turn this into a document-term matrix with the DocumentTermMatrix method:
I used some functions to inspect the DTM, but they aren’t vital but you might want to check out: colnames(), inspect(), and findFreqTerms(). Finally I wanted to just do something with the document-term matrix, so I went with the classic wordcloud. I installed the wordcloud package and, found the word_frequency and generated the wordl as such:

The wordl in this case is made up mainly of the characters who have running story lines.

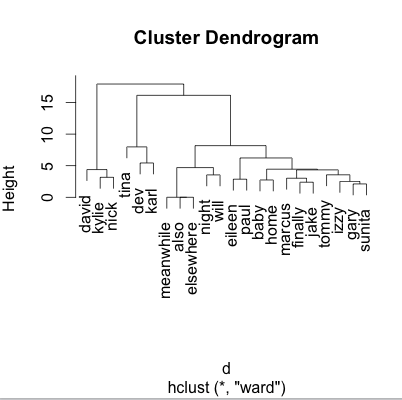
It was also possible to see how far apart words are to give us an idea of related words. I did this
Which gave me a cluster dendrogram, unfortunately at this stage it doesn’t make much sense! The next steps would be to feed the script more data. With more coronation street spoilers the names might not be as prominent.
Next steps
1) Feed it more data!
2) Compare storylines to Eastenders
3) Try classification techniques
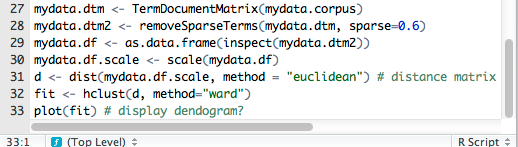
The full script
[codesyntax lang=”text”]
library(“tm”)
corpus <-Corpus(DirSource(“cs”))
corpus.p <-tm_map(corpus, removeWords, stopwords(“english”)) #removes stopwords
corpus.p <-tm_map(corpus.p, stripWhitespace) #removes stopwords
corpus.p <-tm_map(corpus.p, tolower)
corpus.p <-tm_map(corpus.p, removeNumbers)
corpus.p <-tm_map(corpus.p, removePunctuation)
dtm <-DocumentTermMatrix(corpus.p)
findFreqTerms(dtm,4)
library(“wordcloud”)
word_frequency <- colSums(as.array(dtm))
wordcloud(names(word_frequency), word_frequency, scale=c(3,.5),
max.words = 75, random.order=FALSE, colors=c(“lightgray”, “darkgreen”, “darkblue”), rot.per=.3)
[/codesyntax]



0 Comments