Something I had been meaning to do for a long time was write a quick script to scrape Reddit comments. A chap has beaten me to it and you can find the code here: https://github.com/ctaggart878/redditscraper.
During lunch today I had a little play with it the script (and I mean quick!). A two line script imported the function and ran it over the comments in ukpolitics for this week. The two lines:
source(“RedditScraper.R”)
redditScrape(‘ukpolitics’,’week’ )
Here is the magical wordcloud it created:
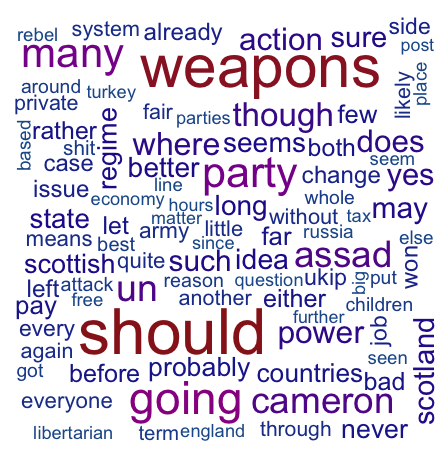
Reddit comments in ukpolitics Aug 28th – Sep 4th
And the top words for the week are Weapons, Many, Should, Cameron, Going. I guess you can tell what’s been on peoples minds. My next steps are to have a closer look at the function, see what it does and see if I can bend it to do some of the things I am doing. I wonder if I can do something with Topic Models to explore what each subreddit is really about. Anyway best get back to real work.
Big thanks to /user/Snotaphilious



4 Comments
Tagg Grant · September 5, 2013 at 8:03 pm
David,
Good luck with the script! Hopefully it’s useful.
I’ll keep an eye on your blog and look forward to your thoughts on what certain subreddits are really about. Sounds like it could be fascinating.
Best,
Tagg
David Sherlock · September 5, 2013 at 8:09 pm
Thanks for the script. I’m currently working on a few scripts that make generates a users personal corpus based around many of the websites they engage with, I guess the idea is so that the user can work out what sort of audiences and resources they are engaging with. The script is just perfect for me.
Many thanks
David
Tagg Grant · September 5, 2013 at 8:11 pm
That sounds like a great project. I’ll definitely keep an eye on what you’re up to.
Best of luck,
Tagg
Topic Models in R Comments ← David Sherlock · September 11, 2013 at 1:23 pm
[…] a user at reddit wrote a post to scrape R comments and I had a play with it here. I’ve just had a very quick play of combining some stuff I’ve written for the Personal […]