I’m still thinking about analysing the personal corpus. I have a basic app written in R that can retrieve, store and analyse data. Retrieving and storing data is easy, but how exactly do we analyse it? I guess that’s where I’m at with R. I’m OK at coding things up. I just don’t understand the statistical methods behind it. Anyway I’m tired and grumpy and not in the mood to read some papers so I’ve decided to listen an album and play with some of the tools instead. I’m starting with LDA.
LDA is an example of a topic model. I seem to be under the impression Andrew Ng has something to do with its history, which could be the reason I’m drawn to it. Apparently it’s similar to probabilistic latent semantic analysis except that each topic distribution must have a Dirichlet prior. I have no idea what that means. If you do could you leave me a comment. Maybe I’ll ask ELI5.
There seen to be two package capable of LDA; topicmodels and lda. I’m going with the topicmodels package because it seems to be the mostly widely used and trusted. Apparently topicmodels is basically a wrapper for David Blei’s work, so I guess you can’t really go wrong with that although the lda apparently has text mining facilities built into it, but since I quite like the tm package and have got reasonably used to it I think I’d like to keep them separate anyway.
Searching through stats.statexchange.com came across a helpful chap with some examples. It’s Ben Marwick again. Maybe I should get in touch with him . He’s using tweets as his datasource. I had a go with my datasource. Lots of fancy stuff came up, including this:
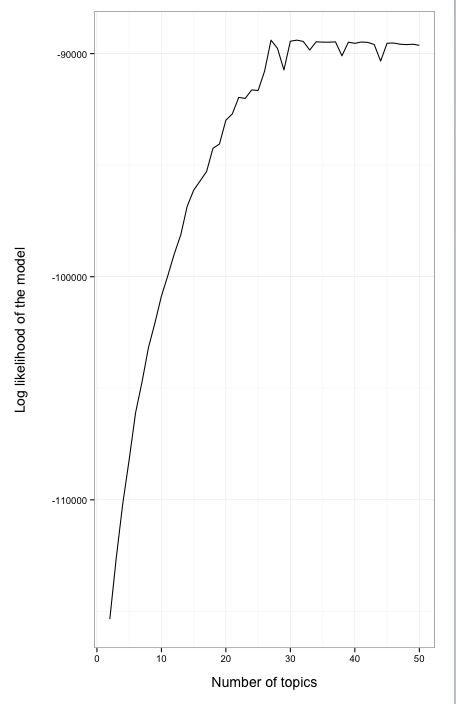
No Idea
I don’t know what I’m looking at. I did find a good introduction to modelling though which I’m going to read before I have another go. Some other things I came across that need more attention:
David Blie’s work. http://www.cs.princeton.edu/~blei/topicmodeling.html
PVclust: http://www.is.titech.ac.jp/~shimo/prog/pvclust/

0 Comments