Getting my head around topic modelling has certainly made me feel stupid. I think part of the problem is that I am just so used to the paradigm I have for searching electronic documents (when I ‘Google’ something), that I am unable to think about exploring documents any other way . This is my first blog post/shot at an attempt of getting my head around this, I don’t claim to be an expert and you should probably take this with a pinch of salt.
From what I understand Topic Modelling allows us to explore documents based on themes that run through that set of documents, we can see how themes are related and the keyword style of searching is replaced with a topic based approach. This is useful because as more information becomes available keyword search just doesn’t really give us productive methods for searching this information. Topic models also allow us to organise and summarize this information, we can model connections between topics. I’m particularly interested in topic models on things that are text, for example video. But lets take baby steps.
Latent Dirichlet Allocation
David Blei, who is one of the great topic modelling wizards claims the simplest form of topic model is Latent Dirichlet Allocation, my reading of this on Wikipedia however suggests that either he is lying or I am in for one hell of a learning experience. Anyway after reading and letting it sine in I found the key law that LDA seems to live by is this:
Documents exhibit multiple topics
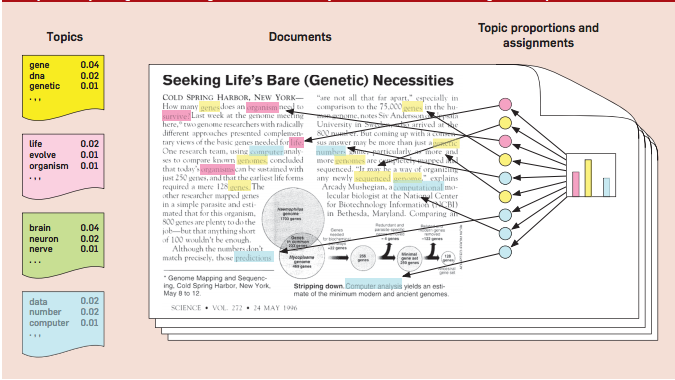
David Blei’s Instutions behind LDA diagram. Source
Blei has done a nice diagram to show how LDA thinks documents exhibit multiple topics. A topic is basically a list of words and the chance that the word will be in the document. The rules are as follows:
- Each document is a random mixture of corpus-wide topics
- Each word is drawn from one of the topics
At this point Im sure I’m missing something. I think its something to do with how we randomly choose the topics. I guess it’s like rolling a massive dice. I guess the process, which is called a generative process and goes something like this:
- Choose a distribution over topics
- Draw a topic from them for each word
- look up distribution
- look up word in that distribution
We repeat this process for each document, but we are randomly drawing topics, so it will be different for each document. Is that right? Who knows?
To be honest I’m not sure I’m getting it.

0 Comments