Previously I’ve mentioned how valuable Stack Overflow is as a resource when getting into a new such as R but yet again I’ve been blown away by just how generous people are with their time.
Last week I was incredibly stuck using R. I had been stuck on the same problem for 2 days. You can find my full problem on stackover, but this was the main aspect of it:
‘I have got text documents, in each document I have text featuring tv series spoilers. Each of the documents is a different series. I want to compare the most used words of each series, I was thinking I could plot them using ggplot, and have ‘Series 1 Terms that occur at least x times’ on one axis and ‘ ‘Series 2 Terms that occur at least x times’ on another. I expect what I need is a dataframe with 3 columns ‘Terms’, ‘Series x’, ‘Series Y’. With series x and y having the number of times that word occurs.‘
Looking back it was no wonder I was stuck. I guess I had three problems, firstly I didn’t understand the data structure, secondly I didn’t know enough about the functions in the tm package and finally I didn’t really know the steps that I was supposed to do. In the end I thought I’d solved it. I won’t post the answer here because it wasn’t a very good solution. At the time however I thought it was a great solution and posted my solution it on the stackoverflow page in case anybody else needed help.’
What happened next blew me away. A chap under the name Ben told me the problem with my code and then proceeded to break my problem down into 5 steps. He then explained very clearly why each step was relevant. You seriously can’t buy that kind of education.
I’m not trying to rip off and claim Ben’s knowledge here. All credit goes to him. This post just serves to do three things; firstly it should help me better understand Ben’s code because if I write it down it helps me. Secondly it will act as reference to me in the future. Finally this is a big thank you to the guy. I couldn’t find a blog or website on his profile for me to link to but you can learn lots about R by reading his answers on stackover.
The Problem
I have a directory with two text documents in them. Each text document has spoilers from a soap opera in them (If you live in the UK you might be interested to know they are spoilers for Coronation Street and Eastenders). I wanted to compare the terms that they used.
The Solution
The first bit I could do myself, this was to read the files from a directory, remove stop words and the such from the corpus and make a DocumentTermMatrix
require(“tm”)
corpus <-Corpus(DirSource(“corryeast”))
corpus.p <-tm_map(corpus, removeWords, stopwords(“english”)) #removes stopwords
corpus.p <-tm_map(corpus.p, stripWhitespace) #removes stopwords
corpus.p <-tm_map(corpus.p, tolower)
corpus.p <-tm_map(corpus.p, removeNumbers)
corpus.p <-tm_map(corpus.p, removePunctuation)
my_stopwords corpus.p dtm <-DocumentTermMatrix(corpus.p)
dtm
Ben told me some key functions that I didn’t know about to help me poke the data:
# find most frequent terms in all 20 docs
findFreqTerms(dtm, 2, 100)
# find the doc names dtm$dimnames$Docs [1] “127” “144” “191” “194” “211” “236” “237” “242” “246” “248” “273” “349” “352” “353” “368” “489” “502” [18] “543” “704” “708”
# do freq words on one doc
findFreqTerms(dtm[dtm$dimnames$Docs == “corry”], 2, 100)
He also showed me how to find the most freq terms for each document. This was useful because I’d been struggling to understand the apply functions and an example personal to me really helped.
# find freq words for each doc, one by one
list_freqs function(i) findFreqTerms(dtm[dtm$dimnames$Docs == i], 2, 100))
There was plenty of other things he showed me how to do, you can check them out on the stackoverflow page.
After poking around the data the next step was to convert to a matrix and then make a dataframe with terms and the number of times a word appears. One thing I was struggling with how to remove rows that had two few terms, he put in a line that added the rows up and let me remove anything that was too few.
# convert dtm to matrix
mat <- as.matrix(dtm)# make data frame similar to “3 columns ‘Terms’,
# ‘Series x’, ‘Series Y’. With series x and y
# having the number of times that word occurs”
cb <- data.frame(Coronation_Street = mat[‘corry’,], Eastenders = mat[‘east’,])# keep only words that are in at least one doc
cb <- cb[rowSums(cb) > 4, ]
and finally plotted..
# plot
require(ggplot2)
ggplot(cb, aes(Coronation_Street, Eastenders)) +
geom_text(label = rownames(cb),
position=position_jitter())
While the outcome may not seem exciting it is really just proof of concept.
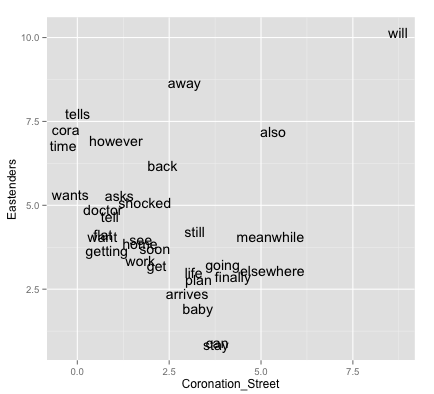
What does it tell us? Well I guess Eastenders are always ‘telling’ people things. Sounds about right for a Londoner. ‘Will’ is the word used both by most spoilers. Will we ever find out why? Tune in next week…
Final Code:
[codesyntax lang=”text”]
require(“tm”)
corpus <-Corpus(DirSource(“corryeast”))
corpus.p <-tm_map(corpus, removeWords, stopwords(“english”)) #removes stopwords
corpus.p <-tm_map(corpus.p, stripWhitespace) #removes stopwords
corpus.p <-tm_map(corpus.p, tolower)
corpus.p <-tm_map(corpus.p, removeNumbers)
corpus.p <-tm_map(corpus.p, removePunctuation)
my_stopwords <- c(stopwords(‘english’), ‘laurens’, ‘gary’, ‘scarlett’, ‘ian’,’max’,’billy’,’craig’,’dennis’,’frank’,’roy’,’leanne’,’joey’,’janine’,’jay’,’tanya’,’kirsty’,’lauren’,’peter’,’nick’,’david’,’faye’,’izzy’,’jason’,’abi’,’anna’,’carl’,’emily’,’gail’,’hayley’,’jason’,’jean’,’kylie’,’lucy’,’michael’,’norris’,’owen’,’sam’,’tim’,’tina’ )
corpus.p <- tm_map(corpus.p, removeWords, my_stopwords)
dtm <-DocumentTermMatrix(corpus.p)
dtm
findFreqTerms(dtm, 2, 100)
# find the doc names
dtm$dimnames$Docs
#findFreqTerms(dtm[dtm$dimnames$Docs == “corry”], 2, 100)
#list_freqs <- lapply(dtm$dimnames$Docs,
# function(i) findFreqTerms(dtm[dtm$dimnames$Docs == i], 2, 100))
#list_freqs
# convert dtm to matrix
mat <- as.matrix(dtm)
# make data frame similar to “3 columns ‘Terms’,
# ‘Series x’, ‘Series Y’. With series x and y
# having the number of times that word occurs”
cb <- data.frame(Coronation_Street = mat[‘corry’,], Eastenders = mat[‘east’,])
# keep only words that are in at least one doc
cb <- cb[rowSums(cb) > 4, ]
# plot
require(ggplot2)
ggplot(cb, aes(Coronation_Street, Eastenders)) +
geom_text(label = rownames(cb),
position=position_jitter())
[/codesyntax]



6 Comments
Ben Marwick · July 6, 2013 at 8:04 am
Thanks for your generous acknowledgement! Looks like you’re making great progress text mining with R. If you’re into text mining tv shows, you’ll probably find this interesting: http://www.prochronism.com/
David Sherlock · July 8, 2013 at 7:22 am
Well it was all your work, thank you for the pointers. That blog looks full of great ideas, I’ll have a poke around it.
David Sherlock · July 17, 2013 at 2:13 pm
Funnily enough I’ve come across your work again, totally by coincidence. Trying to get my head around ngrams in R I’ve found some of your gists via Google. I haven’t managed to get them to work yet though.
Paddy 2013 post roundup · January 2, 2014 at 10:54 am
[…] July: Comparing words in Eastenders and Coronation Street Spoilers: Because Londoners always ‘Want’ stuff apparently. […]