A while ago I used a combination of Facepager and R to find reoccurring phrases in the comments section of the BNP’s Facebook page. The idea was based around a conversation with a friend where I explained that I found it hard to talk to BNP supporters because I just couldn’t get to grips with where they were coming from, I wondered if we could use data mining techniques to get an idea of what makes people with extremist political views tick. I also wondered if we could use similar techniques over news articles to find out which news stories these types of people grasped on to an why.
While originally I wrote a script to work with the BNP’s Facebook data, I have now updated my script to include other UK political parties and an insane organisation Britain First. I’ve just realised that I have forgotten UKIP, while temporary forgetting UKIP is a pleasant experience that I recommend to everybody it has left me annoyed that I will have to run the script again and update the post.
Just to reiterate what I am doing; I am using Facepager to grab the last 10 pages of posts from the Facebook profiles of various political organisations, then I am digging down further to grab the comments on each of these posts; it is this data I am finding ngrams in.
You can find the script at the end of my post, the file it generated was huge and I’m not a pro at making data look good so you will have to put up with this huge image it has generated (click to enlarge):
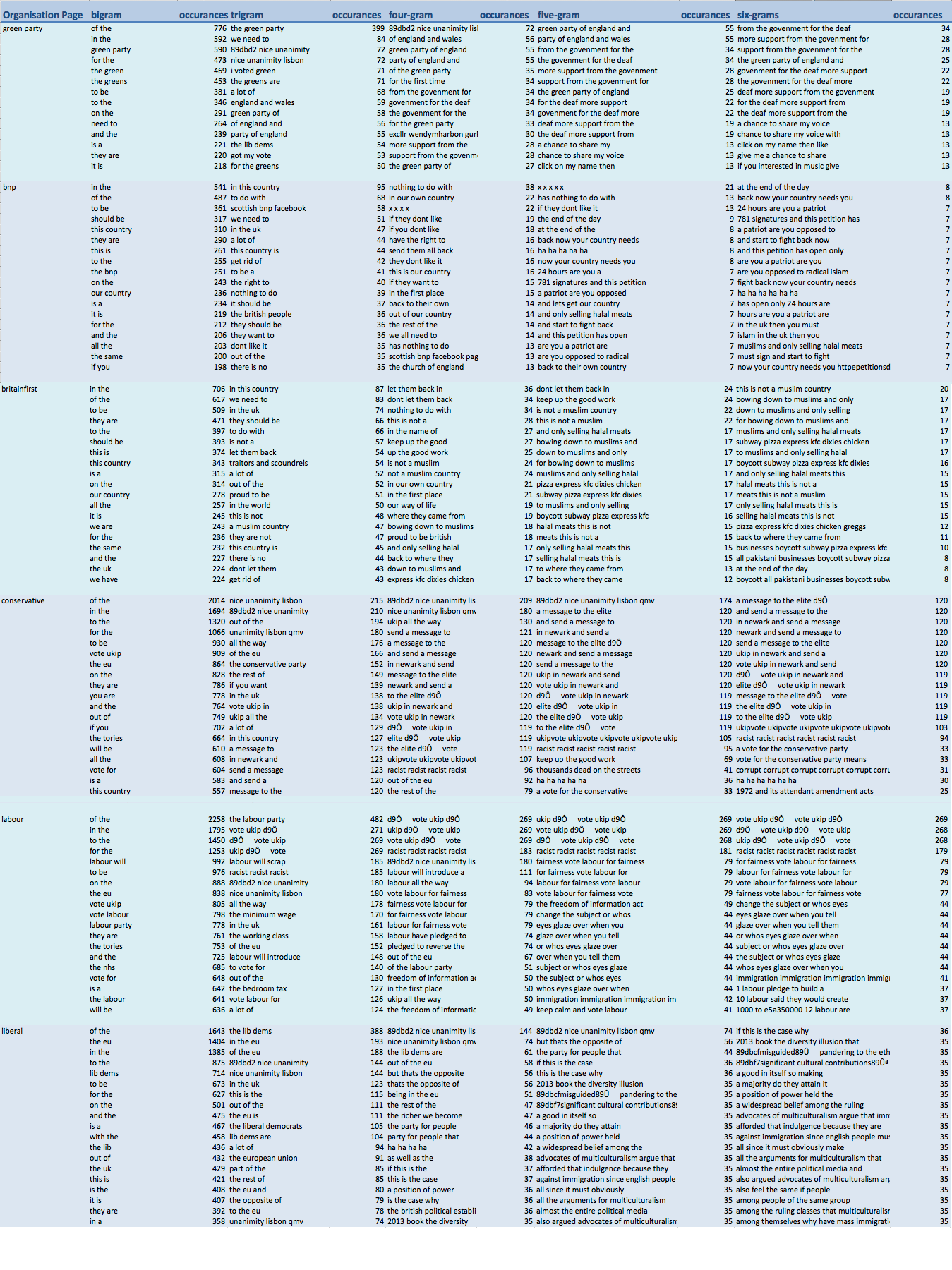 I’ve not had time to go through the data but there are still some interesting observations that may be worth investigating. I think what really stands outs is that data mining doesn’t give you any answers on its own. It just gives you more questions and you really need to know the data well. Here are my immediate thoughts:
I’ve not had time to go through the data but there are still some interesting observations that may be worth investigating. I think what really stands outs is that data mining doesn’t give you any answers on its own. It just gives you more questions and you really need to know the data well. Here are my immediate thoughts:
1) The curious case of “89dbd2 nice unanimity lisbon”
This is a phrase that pops up in the comments on Green Party, Conservative, Labour and Liberal Democrat pages and I guess it is to do with qualified majority voting. It’s still interesting that the phrase pops up and I will have to find out what was in the news and why explore the dataset to see why it comes up (could be spam, see #2). The 89dbd2 is also puzzling and why do all the patterns across all the parties include it? Does this suggest that the comment is copied and pasted across party message boards and the letters are some kind of shortcode the Facebook API uses?
2) It is difficult to separate real opinion and spam
Both Labour and Conservative posts were dominated with comments containing the phrase “vote ukip” or a variant of it. Many of the phrases looked like spam rather than a legitimate opinion or comment. The phrases was also littered with the odd looking code “d9Ô”. I wonder what this is, I wonder again if it is a short code or encoding error? It appears that this is more of a problem the more popular the party. Which makes sense I guess, if you want to spam a message then I guess you post it to the most popular page.
3) Are there lots of issues in the green party around the deaf?
Again – until I have explored the data set further it is hard to tell is something is a message that is being spam or a legitimate capture of a recurring phrase, but it seems that issues around the death have lots of support from the green party with the phrase “support for the deaf” and variants of it being the most common in the Green Party data set. Before I go and explore the dataset it really does make me think through the issues with data, are these spam comments or was a particular post around deafness shared more? Perhaps the greens have lots of polices regarding help for the deaf that I was unaware of? Maybe there was a big news story regarding the lack of support for the death?
4) At the end of the day
My absolutely favorite thing about this data set is that the biggest six-gram from the BNP was the phrase “at the end of the day”. The phrase uttered when there isn’t an argument because it’s just common sense, guv.
5) Supporters of BNP and Britian First are obsessed with “this country”, what people should be doing and practically anything to do with Islam
In most of the data sets the most popular tigram is the names of the party, for example “the green party” or “the labour party”, which was true for all the parties apart from the BNP and Britian first, which both went with “in this country”. Both of these parties were telling people what they should be doing with phrases like “it should be”, “we need to”, “they should be”, “get rid” and of course “if they don’t like it” you can “send them back”. Muslims really get a hard time in the 6-grams column with “this is not a muslim country” and similar variants coming top for Britian First. It’s all very predictable in fact I’m thinking of making a hate speech phrase generation app using this data so you can fit in down your local skinhead pub.
I used Facepager to generate the CSV, here is my R script:
setwd("~/Desktop/comments on pages")
options(mc.cores=1)
#import packages
#install.packages("tm")
#install.packages("RWeka")
#install.package("slam")
library(tm)
library("RWeka")
library("slam")
#import csv
mydata = read.csv("liberalcsv.csv") # read csv file
#prepare text
corpus <- Corpus(VectorSource(mydata$message)) # create corpus object
corpus <- tm_map(corpus, function(x) iconv(x, to='UTF-8-MAC', sub='byte'))
corpus <- tm_map(corpus, mc.cores=1, removePunctuation)
#corpus <- tm_map(corpus, removeNumbers, mc.cores=1)
#corpus <- tm_map(corpus, removeWords, stopwords("english"), mc.cores=1)
# convert all text to lower case
corpus <- tm_map(corpus, tolower, mc.cores=1)
#proplem with to lower means we need to make it type of plain text document again
corpus <- tm_map(corpus, PlainTextDocument)
#make the term document matrix
#tdm <- TermDocumentMatrix(corpus)
for (i in 2:6 ) {
nam <- paste( i, "grams", sep = "")
#tokenizer for tdm with ngrams
BigramTokenizer <- function(x) NGramTokenizer(x, Weka_control(min = i, max = i))
tdm <- TermDocumentMatrix(corpus, control = list(tokenize = BigramTokenizer))
#create dataframe and order by most used
rollup <- rollup(tdm, 2, na.rm=TRUE, FUN = sum)
mydata.df <- as.data.frame(inspect(rollup))
colnames(mydata.df) <- c("count")
mydata.df$ngram <- rownames(mydata.df)
#newdata <- mydata.df[order(-count),]
newdata<-mydata.df[order(mydata.df$count, decreasing=TRUE), ]
assign(nam, newdata )
filename<-paste(i,"gram",".csv")
write.csv(newdata, file = filename)
}

1 Comment
Using Facepager to find comments on Facebook page posts - David Sherlock · May 7, 2015 at 7:24 am
[…] party pages) and then it finds repeated phrases. If you would like to see what I did with it then you can read this post about it here. Hope it […]