I’m currently trying to write scripts for Google Apps that poke around with Reddit API and save results in Google Spreadsheets. I’m finding hard to learn both the Reddit API and Google Scripts at the same time (despite much appreciated help from @mhawksey and @brucemcpherson) . In an attempt to keep my sanity I am routinely returning to Python/Raspberry pi and other things I am more familiar with. Eventually one thing I would like my Google scripts to do is mine comments to gauge what the conversation is about is about. As a test I wanted to write a quick script that could take a text file full of words or phrases and could then check how many times each of these words was used. So, for sanity reasons I am first writing this in Python to be ran on my Raspberry Pi, later I would like to create a Google Script that constantly monitors Reddit and updates a Google Spreadsheet with the mention counts.
1. Install praw
You need the Python Reddit API wrapper. Install with:
pip install praw
2. Create a text document
You then need to create a text document with one word or phrase per line. I decided to see how many times each of the party leaders in the UK general election were discussed by their full name. This is what my full document looked like:
David Cameron
Ed Miliband
Nick Clegg
Nigel Farage
Natalie Bennett
Nicola Sturgeon
Leanne Wood
My script will only look for these full phrases, it will not count anything that is in a different case or any parts of the phrase. For example Nigel Farage will count towards the total but Nigel by itself will not.
3. Write script:
The following script reads all the lines in the file in to a list. It then goes through all the comments in a subreddit (in this instance r/UKpolitics) and prints a count every time that a phrase is found. Due to the API limits and the default settings of PRAW it will take the last 1000 posts in the subreddit before continuing to listen for any future changes. You can run the script with Python <scriptname.py>
import praw
from praw.helpers import comment_stream
r = praw.Reddit("Change me")
r.login()
with open('leaders.csv') as f:
lines = f.read().splitlines()
count = {}
processed = []
for line in lines:
count[line] = 0
while True:
for c in comment_stream(r, 'ukpolitics'):
for line in lines:
if str(line) in c.body and c.id not in processed:
count[line] = count[line] + 1
processed.append(c.id)
print count
4. Results
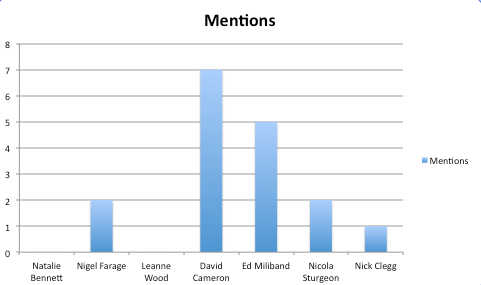
When I ran this the numbers were very low, I think this is because people tend to use surnames for certain politicians, for example Nigel Farage is simply referred to as Farage. My next step is to add the ability to find surnames and then create a live tracker. Hopefully using Google Spreadsheets and the such. I also want to up the amount of words I’m looking for, now, where was that list of ever wrestler ever that I got from DBpedia?

0 Comments